





A DeepMind, uma empresa da Alphabet (a dona do universo Google) que se dedica ao estudo da inteligência artificial, desenvolveu um software capaz de produzir uma voz humana realista a partir de textos escritos. Trata-se do WaveNet, um programa de TTS (text-to-speech, em português o equivalente a “texto-para-voz”) totalmente diferente dos que existem atualmente.
O ouvido humano é capaz de distinguir automaticamente a voz de uma pessoa da voz robótica, que tem uma entoação diferente da natural. É que os programas existentes funcionam através de uma base de dados de sons gravados, que são combinados consoante o texto que é introduzido e geram um som pouco natural, apesar de percetível.
A grande barreira que faltava ultrapassar, para os investigadores da área da inteligência artificial, era precisamente esta: passar do meramente percetível para o humanamente realista. De acordo com a informação divulgada pela DeepMind, a ferramenta é “capaz de gerar discursos que mimetizam qualquer voz humana e que soam mais naturais do que os melhores sistemas de text-to-speech existentes, reduzindo a diferença para a voz humana em mais de 50%“. Além da voz, a empresa garante que o software é capaz de gerar “outros sinais áudio, como música”.
[Ouça aqui uma frase experimental, em inglês, produzida inteiramente com o WaveNet]
Conversar com computadores é “um sonho antigo”, explica a DeepMind, sublinhando que nos últimos anos, a introdução do reconhecimento de voz nos computadores representa uma revolução. Mas a síntese discursiva por parte de dispositivos eletrónicos “ainda é maioritariamente baseada no chamado ‘TTS concatenativo’, em que uma enorme base de dados de pequenos fragmentos de discurso são gravados, por um único locutor”. O grande problema é que se torna “difícil modificar a voz (para outro locutor ou para alterar a emoção do discurso) sem ter de gravar uma base de dados inteira novamente“.
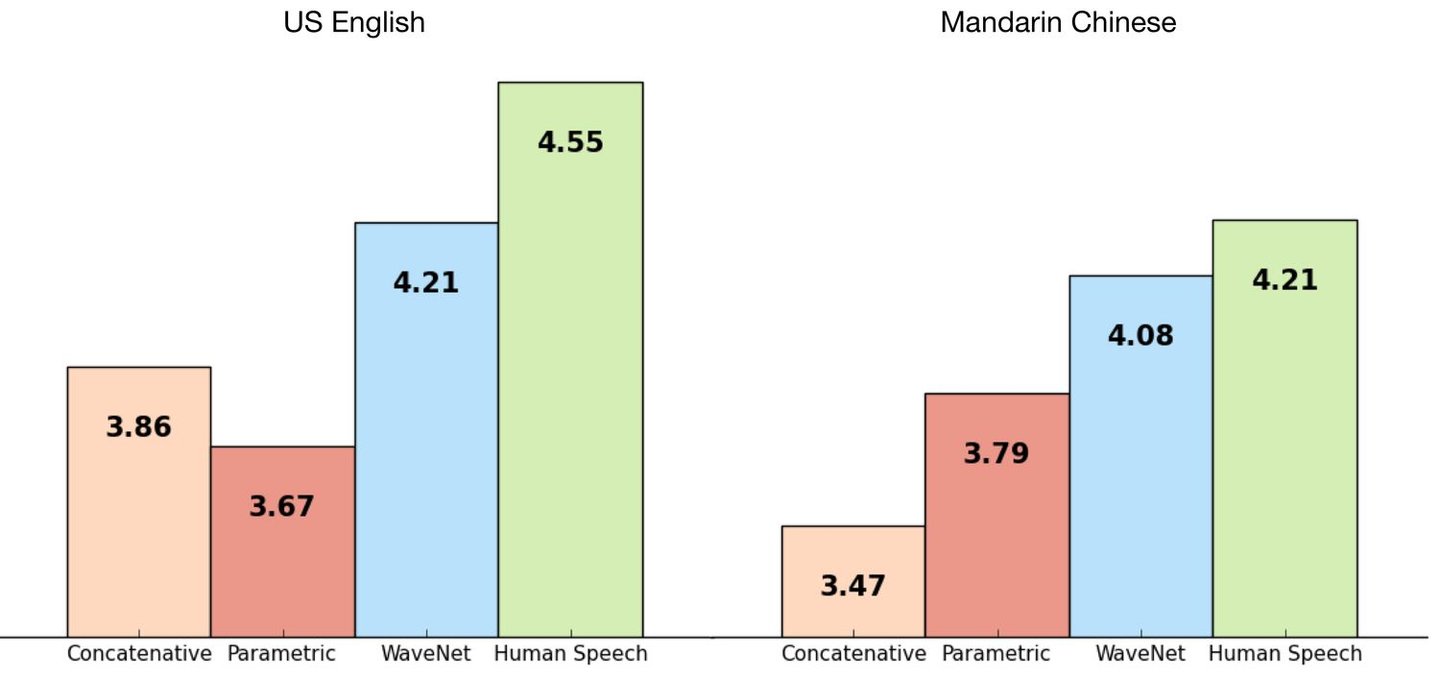
Este gráfico mostra a comparação entre os softwares concatenativos, paramétricos, o WaveNet e o discurso humano real, em inglês e em mandarim.
A primeira tentativa de contornar o problema foi o desenvolvimento de um sistema TTS paramétrico, ou seja, “em que toda a informação necessária para gerar os dados está armazenada em parâmetros do modelo, e os conteúdos e características do discurso podem ser controlados através de informação introduzida nesse modelo”. Contudo, o som produzido soava ainda menos natural do que os sistemas concatenativos.
É aqui que entra o WaveNet. Em vez de depender de uma base de dados pré-gravada para modelar o discurso, este programa da DeepMind é capaz de modelar a onda sonora digital. “Usar ondas em bruto significa que o WaveNet consegue modelar qualquer tipo de áudio, incluindo música”, explica a empresa. Em teoria, o software é capaz de produzir, literalmente, todos os sons do mundo. É só construir a onda correspondente.
O software é capaz de moldar cada ponto de uma onda sonora. É como construir uma fotografia píxel por píxel.
A DeepMind desenvolveu o WaveNet inspirada por dois softwares de edição de imagem: o PixelRNN e o PixelCNN, que são modelos que permitem a construção de imagens naturais píxel a píxel. E o programa é tão preciso que até produz, de forma aleatória, sons de respiração e de movimentos da boca.
Conversar fluentemente com computadores parece agora estar um passo mais perto. Numa altura em que os softwares de reconhecimento de voz, como o assistente pessoal Siri da Apple, se estão a tornar populares, a Google tem no WaveNet uma oportunidade de criar o primeiro programa capaz de falar de igual para igual, foneticamente falando, com um ser humano. O primeiro passo está dado: colocar um computador a produzir uma voz realista. Resta saber quando é que os computadores vão ter a capacidade de nos responder como gente.














