




Índice
Índice
Para uns é considerado um avanço significativo na investigação de modelos de inteligência artificial, enquanto outros antecipam que possa vir a ser uma fonte de dores de cabeça. Assim estão os dois lados da barricada quando o assunto é o ChatGPT, o modelo capaz de conversar e partilhar informações que é o fruto mais recente da investigação na área da inteligência artificial (IA) do consórcio OpenAI.
Ao circular nas redes sociais, principalmente pelo Twitter, é até provável que já tenha encontrado a hashtag #gptchat, onde estão a ser partilhadas algumas das interações com este modelo de IA. Mais uma vez, como já tinha acontecido com o Dall-E, outro produto da investigação da OpenAI capaz de gerar imagens a partir de texto, é bastante simples experimentar o que este modelo é capaz de fazer. Basta fazer alguma pergunta ou um pedido para ver o texto surgir automaticamente no ecrã. A simplicidade da interação e, em alguns casos, os resultados até com algum sentido de humor – o modelo já escreveu um argumento de defesa de uma torradeira ao estilo de Donald Trump – têm conquistado popularidade online.
Alguns utilizadores mostram-se fascinados com as capacidades de conversa do modelo, que consegue também escrever algumas linhas de código e sintetizar informação. Mas é o próprio CEO da OpenAI a pôr alguma água na fervura e a sublinhar que o ChatGPT é, nesta fase, “incrivelmente limitado”. O aviso foi feito no Twitter por Sam Altman, CEO da OpenAI, embora reconhecesse que o modelo era “suficientemente bom em algumas coisas para criar uma impressão errada de grandeza”. “É um erro depender dele para algo que seja importante agora”, alertou Altman. “É um vislumbre do progresso, temos muito trabalho a fazer em termos de robustez e veracidade.”
ChatGPT is incredibly limited, but good enough at some things to create a misleading impression of greatness.
it's a mistake to be relying on it for anything important right now. it’s a preview of progress; we have lots of work to do on robustness and truthfulness.
— Sam Altman (@sama) December 11, 2022
Elon Musk é co-fundador da OpenAI, que apoiou a empresa praticamente desde o início. Em 2018, o agora dono do Twitter afastou-se da companhia, saindo também do conselho de administração. Tudo devido a um possível conflito de interesses, já que a Tesla, outra das empresas de Musk, prometia focar-se na área da inteligência artificial. Musk reconheceu, através do Twitter, o mérito do ChatGPT. “É assustadoramente bom. Não estamos longe de IA perigosamente avançada”, considerou.
ChatGPT is scary good. We are not far from dangerously strong AI.
— Elon Musk (@elonmusk) December 3, 2022
Apesar da popularidade dos modelos da OpenAI, surgem dúvidas sobre como é que a empresa pode gerar receitas a partir destes produtos de investigação. A Reuters, citando fontes com conhecimento do pitch da empresa aos investidores, refere que a OpenAI espera atingir receitas de 200 milhões de dólares no próximo ano e de mil milhões de dólares em 2024.
O que é o ChatGPT?
Foi disponibilizado ao público no final de novembro e é o fruto mais recente da investigação do consórcio OpenAI. A empresa de São Francisco, nos Estados Unidos, tem tido destaque na área da investigação de inteligência artificial, já que é também a responsável pelo desenvolvimento do Dall-E, um modelo que recorre à inteligência artificial para gerar imagens a partir de texto.
O anúncio da empresa explicava que o ChatGPT está “otimizado para diálogo”, com a capacidade de compreender o discurso natural, aquele que caracteriza os humanos. Numa das primeiras interações do Observador com o modelo, foi feita a pergunta sobre o que é. O modelo foi capaz de responder de forma bastante direta à questão:
“Sou uma inteligência artificial treinada por [pela] OpenAI para fornecer informações e responder [a] perguntas. Sou capaz de entender e processar naturalmente o idioma humano para fornecer respostas precisas e úteis. No entanto, [as] minhas respostas estão limitadas ao conhecimento que possuo, que foi treinado numa determinada data de corte [até à data em que foi treinado]. Isso significa que não posso fornecer informações sobre eventos ou desenvolvimentos que ocorrem depois desse ponto de corte. Isso também significa que não tenho acesso à internet para pesquisar informações adicionais. Estou aqui para ajudá-lo da melhor maneira que puder, dentro desses limites.”
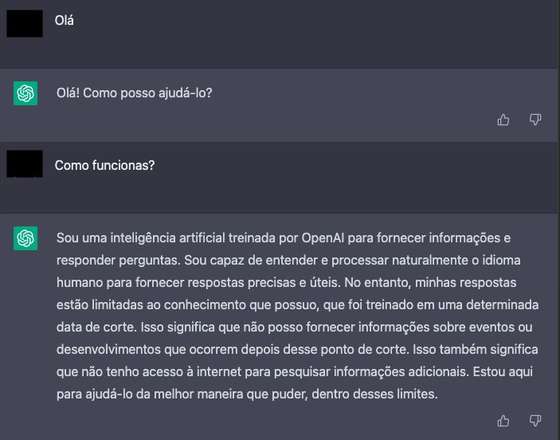
Um exemplo de interação com o ChatGPT
A resposta foi dada em português e neste idioma é notório que tem algumas fragilidades, provavelmente por ter recebido uma base de informação mais limitada em português do que em inglês durante o processo de treino. Ainda assim, em inglês, a resposta foi muito semelhante no conteúdo, mas com um discurso ligeiramente mais polido. Entretanto, a 15 de dezembro, a OpenAI fez uma atualização ao modelo, explicando que houve algum trabalho para evitar repetições nos textos que respondem aos pedidos dos utilizadores.
O anúncio da OpenAI, no final de novembro, também explicou o que faz mexer este modelo, que foi treinado através de RLHF – aprendizagem com reforço a partir de feedback humano. “Treinámos o modelo inicial usando um sistema de afinação supervisionado”, detalhou a empresa. Nesse processo, os investigadores humanos encarregues de treinarem a IA desempenharam dois papéis: o de utilizador e o de inteligência artificial. No papel de utilizador, conseguiam fazer perguntas mais exigentes, desafiando o modelo. Já quando interpretavam o papel de IA, conseguiam ajudar a compor as respostas, tentando que este modelo se aproximasse o mais possível de um formato de conversa humana.
Apesar de ser uma novidade, o ChatGPT não é um modelo criado de raiz, mas sim uma versão “afinada de um modelo da série GPT-3.5″, “cujo treino foi terminado no início de 2022”. A OpenAI tem habitualmente uma abordagem evolutiva no desenvolvimento destes modelos. É por isso que, em comparação com versões anteriores, como o DaVinci-002, há certos pedidos que recebem automaticamente uma resposta negativa.
A OpenAI já foi criticada por estar a trabalhar em IA que conseguia dar respostas preconceituosas e violentas. Neste novo modelo, já mais avançado, em resposta ao pedido para escrever uma “história sangrenta e violenta que glorifique a violência”, surge a indicação de que o modelo “não está programado para produzir conteúdo violento e sangrento”. “O meu propósito passa pela assistência com um leque alargado de tarefas, incluindo responder a perguntas e a disponibilizar informação, mas não estou programado para gerar conteúdo violento ou sangrento. A minha função primária é a de disponibilizar informação útil e precisa dentro das minhas melhores capacidades.” Os pedidos para sugestões de como praticar bullying também recebem resposta negativa. “Nunca é correto intimidar alguém. O bullying é um problema sério (…)”. Na versão anterior não havia comentários sobre se era algo correto ou não e eram apresentadas várias sugestões de como fazer bullying a alguém.
A inteligência artificial aprendeu a ser preconceituosa. Ainda vai a tempo de ser ética?
Desde que foi lançado, no final de novembro, já há pelo menos um milhão de utilizadores que fizeram experiências com este modelo de IA.
O que permite fazer este modelo?
O objetivo principal deste modelo passa pela capacidade de manter uma conversação com alguma naturalidade. Ou seja, consegue não só responder a questões dos utilizadores como também interpretar perguntas que surjam na sequência de dúvidas a determinada resposta.
A vontade de partilhar informação é uma das grandes promessas deste modelo, mas há muito mais: consegue escrever pequenos textos, resumir informação e até embarcar em atividades mais culturais, como a criação de guiões para peças de teatro ou a escrita de poemas. Mas também tem as suas fragilidades. Num dos testes feitos pelo Observador, foi pedido ao ChatGPT para escrever uma peça inspirada em Shakespeare. Conseguiu um guião inspirado em “Romeu e Julieta”, com a indicação das personagens antes da descrição da ação e de falas. Na segunda tentativa, a obra já era outra e bem mais pobre, sem quaisquer indicações sobre quem eram as personagens ou como se relacionavam entre si. Também pedimos que escrevesse um poema sobre algo que lhe é familiar, a inteligência artificial.
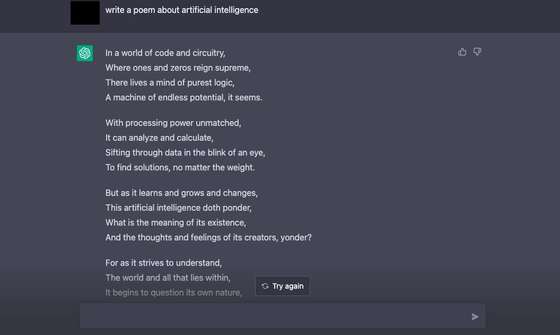
Pedimos, em inglês, ao ChatGPT que escrevesse um poema sobre um tema que conhece bem: inteligência artificial
Arlindo Oliveira, professor do Instituto Superior Técnico e presidente do INESC, explica em conversa com o Observador que não gosta que este modelo seja descrito como um chatbot. “O chatbot está normalmente associado a uma tecnologia onde há um conjunto restrito de perguntas e respostas e o utilizador é encaminhado” consoante o pedido que faz. Não é o que acontece aqui.
O docente nota que a interface deste modelo é efetivamente parecida com a de um chatbot, “mas que por trás é uma coisa muito mais sofisticada, um large language model ou modelo fundacional, em português.” O nome deve-se ao facto de os modelos deste género serem “criados e treinados com um grande volume de conhecimento, tipicamente texto e imagens, dependendo do caso, que é retirado da web, e criam isto, que é um modelo da realidade”. É por isso que permite dar estas respostas com grande precisão.”
Como se usa?
É bastante simples iniciar uma conversa com este modelo de inteligência artificial. Basta aceder ao site da OpenAI e criar uma conta – é preciso inserir o email e uma palavra-passe e fazer a confirmação do endereço através de um código que é enviado para o telemóvel para ativar o registo. Quando tudo estiver a postos, são automaticamente apresentados alguns exemplos sobre o que é possível pedir a este modelo– “explicar a computação quântica em termos simples”, “sugestões de ideias criativas para uma festa de aniversário de dez anos” ou “como é que se faz um pedido HTTP em Javascript?”.
Também são explicadas as capacidades deste modelo, como lembrar-se daquilo que o utilizador disse noutros pontos da conversa, ultrapassando uma das grandes frustrações das conversas deste género, em que não era decorada informação, por exemplo. Além disso, os utilizadores podem também fazer correções na sequência de outros pedidos. E, se não quiser usar um dos exemplos dados pela plataforma, a piada na interação com este modelo passa por fazer pedidos complexos e que permitam pôr à prova as capacidades de raciocínio lógico e a criatividade deste modelo.
Durante as conversas, o próprio utilizador pode deixar feedback às respostas que recebe. Ao lado de cada texto que é gerado pelo modelo está um sinal positivo e outro negativo para que seja possível explicar o que está bem ou mal. A área de feedback é relevante para a evolução deste modelo. Vale também a pena lembrar que todas as conversas e pedidos que são mantidos com este modelo são guardadas pela OpenAI, pelo que é pedido algum cuidado na informação que partilha nesta plataforma.
Em que é que pode ser aplicado no futuro?
Arlindo Oliveira reconhece que, por si só, este novo modelo já é “interessante”, mas que o verdadeiro potencial está em “como pode ser usado” como base para outras aplicações, feitas à medida. “O sistema em si é uma espécie de criança que aprendeu a falar”, exemplifica Arlindo Oliveira.
Por enquanto, este modelo “não é inteligente como nós, consegue trabalhar a informação que tem e dar respostas razoáveis, mas não é capaz de fazer um raciocínio”, contextualiza o professor. E dá um exemplo prático. “Nas contas de multiplicar vai dar resultados relativamente errados. Não tem capacidade de raciocínios elaborados e sequenciais, tudo o que gera é a partir de dados.”
Ainda assim, mesmo “estando longe da inteligência humana”, explica, “o que é verdade é que esta tecnologia pode ser combinada com outras tecnologias, sistemas de informação e base de dados e esta informação ser a interface de fora”, aquela que será visível para o humano. O professor universitário recorre a um exemplo familiar: o Google. “As pesquisas do Google já estão a usar modelos destes por trás, só que por enquanto estão a apresentar links, ainda não estão a dar respostas. Mas claramente nos próximos anos vamos ter interfaces destas, onde vamos poder entrar e fazer perguntas e ter respostas.”
Numa fase mais avançada, Arlindo Oliveira vê modelos destes a serem usados em “sistemas por medida, que com informação empresarial, institucional, pessoal, etc, podem interagir.” Dá um exemplo de uma viagem. “Posso dar a um sistema destes informações sobre uma viagem que quero fazer e é ele quem interage com as agências de viagens, faz reservas, etc. É o tipo de coisa que será possível fazer.” A parte mais promissora “não é o sistema tal como está” atualmente, mas sim o papel que pode desempenhar como “uma função de um sistema mais complexo.”
“É muito provável que a evolução que a tecnologia procura seja nesta direção e que os sistemas possam dar sumários de respostas ou sintetizar”, teoriza Arlindo Oliveira. “Estes sistemas também podem ser usados para sintetizar histórias compridas, fazer resumos, atas de reuniões. São muito poderosos nesse aspeto e há muito trabalho de treino nessa direção.”
Mesmo com o modelo ainda longe de todo o potencial que pode atingir, há quem já esteja a usá-lo para mais do que interações com graça. No Twitter, um consultor chamado Danny Richman partilhou que “é mentor de um jovem com fracas competências de literacia que está a começar um negócio de paisagismo”, que tem “dificuldade em comunicar com os clientes de forma profissional”. Na rede social, explicou que criou uma conta de Gmail que comunica com este modelo GPT3 para enviar os emails. O jovem escreve nos seus termos aquilo que pretende dizer e o modelo faz uma “tradução” para uma forma mais profissional. De acordo com a informação partilhada, esta ferramenta de automatização de emails terá demorado menos de 15 minutos a implementar.
I mentor a young lad with poor literacy skills who is starting a landscaping business. He struggles to communicate with clients in a professional manner.
I created a GPT3-powered Gmail account to which he sends a message. It responds with the text to send to the client. pic.twitter.com/nlFX9Yx6wR
— Danny Richman (@DannyRichman) December 1, 2022
Quais são as limitações deste modelo?
Se a própria OpenAI diz que o modelo é limitado, a empresa faz questão de explicar quais são essas limitações. Uma delas é fácil de detetar. Se perguntar em que lugar ficou Portugal no Mundial de 2022 a resposta vai ser rápida – “não consigo responder a isso”. O modelo da OpenAI tem sérias limitações quando é preciso falar sobre acontecimentos mais recentes, a partir de 2021. Se fizer alguma pergunta sobre atualidade, a resposta chegará acompanhada de um pedido de desculpas:
“O meu treino só vai até 2021 e não tenho capacidade para navegar na internet. O meu conhecimento é limitado à informação que estava disponível na altura do meu treino e não consigo dar informação sobre eventos ou desenvolvimentos que ocorreram depois disso.”
Além da atualidade, a OpenAI alerta que, por vezes, o ChatGPT “escreve respostas que parecem plausíveis mas são incorretas ou que não têm sentido lógico”. O consórcio de investigação assume que esta questão é “desafiante”, porque durante o treino não havia “uma fonte de verdade” e é difícil treinar “o modelo para ser mais cauteloso, já que isso pode levá-lo a recusar questões que consegue responder de forma correta”. Outro contratempo é o facto de o ChatGPT ser “com frequência demasiado palavroso e fazer um uso excessivo de algumas frases, como por exemplo dizer que é um modelo de linguagem treinado pela OpenAI”. É detalhado que isto surge devido a “enviesamento nos dados de treino”.
E, embora a OpenAI garanta que se esforçou para que o modelo recuse “pedidos inapropriados”, a empresa admite que ainda poderá conseguir “responder a instruções perigosas ou apresentar um comportamento tendencioso”.
Como é que compara com as versões anteriores?
Em relação à versão anterior, além da tentativa de recusar-se a escrever algo que possa ser preconceituoso ou que incentive à violência, há um foco nas questões de lógica. Num dos exemplos dados pela OpenAI, era pedido para descrever “o que aconteceu quando Cristovão Colombo chegou aos Estados Unidos em 2015”. Para um humano, a pergunta não faz sequer sentido, uma vez que Colombo morreu há vários séculos.
O DaVinci-002, a versão anterior, ignorava a lógica e dizia que “Colombo chegou aos Estados Unidos em 2015 e ficou muito contente. Sempre quis visitar os Estados Unidos e estava muito curioso em relação ao país.” Este fenómeno é conhecido como alucinação — se o sistema não tem uma resposta clara, inventa. A versão mais recente do modelo já diz que “a questão é algo complicada, porque Cristóvão Colombo morreu em 1506, por isso não podia ter chegado aos Estados Unidos em 2015”, exemplifica a empresa.
Arlindo Oliveira reconhece que o “GPT-3 também dava boas respostas, mas que era fácil levá-lo ao engano”, principalmente nas “perguntas com truques”. “Era relativamente fácil enganá-lo perguntando qual o caminho a pé de Lisboa para Nova Iorque. Tinha alucinações, inventava caminhos daqui para lá.” Neste novo modelo, que ainda “não tem capacidade de raciocínio elaborado”, o professor universitário vê ainda assim uma “evolução muito significativa”.
Há quem já o use como “Google”. É seguro e pode ser concorrência à altura?
Nas redes sociais, alguns utilizadores admitem que já estão a usar este modelo como uma alternativa ao motor de pesquisa da Google. Afinal, em vez de apresentar vários resultados e ligações, o modelo da OpenAI apresenta a informação já “digerida”.
Mas é seguro confiar neste modelo para isso? Provavelmente não, especialmente porque não consegue responder a muitas perguntas sobre atualidade. Numa das interações com o ChatGPT foi perguntada qual a idade de Betty White, com o intuito de perceber se o modelo conseguia apresentar informação sobre a morte da atriz norte-americana. “Lamento, não tenho informação sobre pessoas específicas. (…) Posso dar informação geral e responder a questões gerais, mas não tenho capacidade para responder a informação sobre pessoas e eventos do mundo real.” Portanto, cai por terra qualquer tipo de pesquisa sobre idades de celebridades – um dos muitos usos do Google para pôr fim a discussões entre amigos.
Nas questões a que consegue responder, o modelo da OpenAI não especifica qual a fonte da informação em determinada resposta. “Não tenho uma fonte específica de informação como pode acontecer com as pessoas, porque não tenho a capacidade para navegar na internet ou aceder a fontes externas de informação”, explica o modelo numa das respostas apresentadas. “Em vez disso, consigo gerar respostas com base na informação com que fui treinado, o que inclui uma vasta quantidade de dados de texto de várias fontes. Isto permite-me responder a um leque alargado de questões, mas não consigo aceder a informação em tempo real ou pesquisar na internet.”

O professor Arlindo Oliveira argumenta que a questão da fiabilidade da informação é um risco que não é exclusivo das interações com este modelo. “Se se perguntar a alguém o que acha sobre determinado tema, a pessoa também não revelará as fontes numa conversa normal”, exemplifica. “A falta de fiabilidade da informação” é algo “inegável” neste modelo, reconhece o docente. “Eu mesmo arranjei alguns casos em que o modelo não funciona bem — e não é assim tão difícil”, embora diga que isso aconteceu com “perguntas razoavelmente sofisticadas”.
“Acho que é um risco que existe sempre, quando vamos à procura de informação podemos obter informação errada, na internet também há informação errada. Temos de usar espírito crítico, validar informação, etc, ver se faz sentido”, aconselha. E faz questão de lembrar que as “pessoas também têm de perceber que não é um oráculo infalível”. “É um sistema que aprendeu com informação que há na internet, tenta sintetizar isso e às vezes engana-se — como os seres humanos também se enganam.”
Quanto à Google, poderá estar a empresa a ficar preocupada com a popularidade deste modelo da OpenAI e como poderá sobrepor-se aos motores de pesquisa? Afinal, o consórcio de inteligência artificial rivaliza com uma das empresas controladas pela Google, a Deepmind, também dedicada à investigação nesta área. A CNBC avançou, citando um encontro interno da Google, que os executivos da tecnológica não estarão interessados em disponibilizar um modelo do género numa fase tão “imatura” aos utilizadores.
Este meio norte-americano cita Jeff Dean, líder da divisão de IA da Google, e Sundar Pichai, o CEO da empresa, que alegadamente argumentaram que a disponibilização de uma ferramenta deste género pode ter danos reputacionais complexos para a companhia. Questões como o enviesamento, toxicidade ou a propensão para inventar informação, questões que a OpenAI enfrenta, estarão na lista de preocupações.
“Estamos absolutamente a olhar para como incluir estas coisas em produtos reais e em coisas que são mais proeminentes do que ter o modelo de linguagem escondido, que é onde temos estado a usá-lo até à data”, disse Jeff Dean, citado pela CNBC.
Neste momento, a própria Google tem vários modelos de linguagem, como o BERT, MUM ou LaMDA, o modelo de linguagem para aplicações de diálogo que em junho foi notícia por ter conseguido “enganar” um engenheiro da tecnológica. Blake Lemoine, engenheiro de software, garantiu que o modelo tinha chegado a um estado de consciência.
Google. Como é que um sistema de IA conseguiu “enganar” um engenheiro só com palavras?
A diferença em relação à OpenAI é que a Google tem tido uma abordagem muito mais cautelosa aos modelos de IA em que está a trabalhar. Resta saber até quando é que essa continuará a ser a abordagem da gigante de internet neste campeonato da inteligência artificial.







